转自:
== 目标问题 ==
下一代的Hadoop框架,支持10,000+节点规模的Hadoop集群,支持更灵活的编程模型
== 核心思想 ==
固定的编程模型,单点的资源调度和任务管理方式,使得Hadoop 1.0的应用在模式上和规模上都日益表现出它的局限性。
YARN的核心思想是采用两级分布式的资源调度和任务管理框架,支持模块化的任务调度组件和自定义的任务管理模块,以适应多样化的编程模式和日益增大的集群规模。
YARN以container为单位调度资源和任务,可调度的资源类型为Memory(长期目标包括CPU/DISK/IO等),通过在各个任务管理框架间分配和共享资源来提高集群利用率,整体思想和Mesos十分接近。
== 实现 ==
YARN的主要组成部分包括:
一个全局的RM(ResourceManager),每个Job一个的AM(ApplicationMaster) 和 每个节点一个的NM(NodeManager)
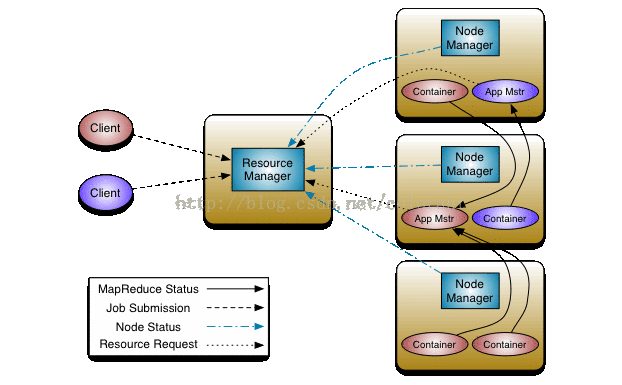
RM内部又进一步分为调度模块(scheduler)和应用管理模块(Applications Manager),调度模块负责在各个Job间调度分配资源,而应用管理模块则负责监听客户端创建Job的请求和启动Per Job的AM
在应用管理模块启动AM以后,AM就接管了自身Job之后的管理工作,AM负责与调度模块协商获取任务运行所需的资源,通过NM创建得到所需资源的任务进程,并监控任务的完成情况。
从AM和RM的通讯协议上看,对资源的调度接口已经简化为一个AM所需Container的配置,数量和位置的列表,因此具有很大的通用性,当然,由于调度模块只是简单的根据Job的需求和优先级等调度资源,而不考虑任何任务具体细节和执行情况的相关信息,也就会损失一些可以作为调度依据的信息。以MapReduce为例,MapSplit相关的信息是调度模块所无法得知的。Locality等要求就需要由AM来保证。
== 相关研究,项目等 ==
Mesos所要解决的问题和整体思路和YARN十分相似。同样的两级资源调度,可模块化的调度策略,由具体的运算框架负责第二级资源调度,隔离的资源管理方式和相似的任务执行方式。不过在资源的一级调度方式上,Mesos采用Push的方式,而YARN采用Pull的方式,Mesos号称是为了使接口更加简单和通用化,YARN采用Pull的方式看起来则似乎更灵活一些。但是光从API上看,个人理解AM在做调度请求前还需要获取全局资源的状态,可能需要付出更大的通讯代价?
Facebook的Corona同样是为Hadoop开发的,基本上也是将MapReduce1.0中的Job tracker以Job为单位进行拆分。同样采用Pull的方式向中央调度模块Cluster manager请求资源。不过Scope大概比YARN要小,目测纯粹是通过分布是调度的方是解决集群规模问题,而YARN同时还希望能灵活适配不同的运算框架。